
Big datasta puhutaan tällä hetkellä paljon. Monet tutkijat tutkivat asiaa ja kirjoittavat siitä. Yliopistot ja muut oppilaitokset kehittävät koulutusohjelmia siihen liittyen. Big datan myötä on jopa syntynyt uusi datatieteilijän (Data Scientist) ammatti, jonka harjoittajat keskittyvät työssään Big datan analysointiin.
Vuonna 2012 uutta dataa luotiin 2,5 exatavua (1018) joka päivä ja on sanottu, että tämä määrä tuplaantuu 40 kuukauden välein. Samoin on arvioitu, että vähittäiskauppayritys Walmart kerää yli 2,5 petatavua erilaista transaktiodataa joka tunti. (Mayer-Schönberger & Cukier, 2013) Onkin varsin todennäköistä, että uuden datan luomisen tahti on vain kiihtynyt vuoden 2012 jälkeen. Tällä perusteella voidaankin helposti ajatella, että tuo uuden datan luomisen määrä on jo tuplaantunut ja tällä hetkellä uutta dataa luodaan varmaankin yli 5 exatavua joka päivä.
Big Datan luonnehdinta
Big dataa voidaan kuvata termillä ”löydetty data” (”found data”). Se on dataa, jota ei välttämättä ole tarkoitettu analysoitavaksi. Se on dataa jota syntyy, esimerkiksi luottokorttiostoksistamme, hauista joita teemme Internetissä ja päivityksistämme erilaisissa sosiaalisen median sovelluksissa, kuten Twitterissä, Facebookissa ja LinkedInissä. (Harford, 2014; McAfee & Brynjolfson, 2012)
Andersonin (2008) mukaan datan eri aikakausia voidaan kuvata seuraavasti: 60 vuotta sitten digitaaliset tietokoneet tekivät informaatiosta luettavaa, 20 vuotta sitten Internet teki informaatiosta saavutettavaa ja 10 vuotta sitten ensimmäiset hakukoneet tekivät Internetistä yhden tietokannan. Vastaavasti kilotavuja tallennettiin erilaisille levykkeille, megatavuja tallennettiin kiintolevyille. Teratavun kokoisia määriä tallennettiin ja petatavut tallennetaan pilveen. (Anderson, 2008)
Esimerkkejä Big Datan soveltamisesta
Paljon julkisuutta Big data sai vuoden 2009 sikainfluessapandemian aikana. Tällöin Googlen tutkijat huomasivat, että he pystyivät ennustamaan CDC:tä (Centers for Disease Control) nopeammin, miten epidemia USA:ssa etenee. Googlen tutkijat huomasivat, että kun he analysoivat 50 miljoonaa Googlella eniten haettua termiä, hakusanat, kuten ”influenssa oireet” ja ”apteekkeja minua lähellä” yleistyivät joillain alueilla. Lisäksi he huomasivat tämän ennakoivan epidemian leviämistä kyseiselle alueelle. (Harford, 2014)
Maailman suurin vähittäistuotteiden myyjä, Walmart kehitti 1990-luvulla ”Retail Link” -järjestelmän, jonka avulla tavarantoimittajat pystyvät seuraamaan myyntimääriä ja voluumejä sekä varastomääriä. Tämän järjestelmän voidaan ajatella perustuvan Big Dataan. Samoin USA:ssa on kehitteillä Big dataan perustuva hanke, jossa järjestelmä auttaa lääkäreitä tekemään parempia diagnooseja liittyen keskosiin. Ohjelma kerää reaaliaikaista dataa, kuten sydämen syke, verenpaine ja veren happipitoisuus. Ohjelma pystyy tällä perusteella havaitsemaan muutoksia keskosten voinneissa ja tällä perusteella ennakoimaan infektioita 24 tuntia ennen niiden puhkeamista. (Mayer-Schönberger & Cukier, 2013)
Joitakin Big Datan analyysimenetelmiä
Big datan kannattajat ovat tehneet neljä mielenkiintoista väitettä Big dataan liittyen. On muun muassa esitetty, että Big datan myötä perinteiset tilastomatemaattiset otantamenetelmät ovat tulleet tarpeettomiksi. Lisäksi on esitetty, että tilastollisia malleja tai tieteellisiä malleja ei tarvita, koska riittävän datamäärän perusteella numerot puhuvat itsestään. Lisäksi on todettu, että korrelaatio kertoo riittävästi siitä, mitä halutaan tietää. Pienen datan kohdalla korrelaatiot ovat hyödyllisiä, mutta Big datan kohdalla ne todella ovat hyödyllisiä. Korrelaatioiden laskenta tarjoaa näkymiä dataan helpommin, nopeammin ja selvemmin, kuin aikaisemmin. (Mayer-Schönberger & Cukier, 2013)
Yksi pisimmälle väitteessä mallien tarpeettomuudesta mennyt on Chris Anderson. Anderson toteaa Wired-lehdessä julkaistussa kirjoituksessaan, että Big Datan myötä malleista on tullut täysin tarpeettomia – data itsessään ”puhuu”. Lisäksi Andersonin mielestä enää ei pitäisi miettiä, mitä Google voi oppia tieteestä. Nyt pitäisikin miettiä, että mitä tiede voi oppia Googlelta. (Anderson)
Seuraavassa on esitelty ja käyty läpi joitakin Big Dataan liittyviä analyysimenetelmiä, jotta saadaan käsitys niistä. Mayer-Schönberger ja Cukier (2013) esittävät, että tärkein Big Datan analysointimenetelmä on korrelaatio. Pienen datan kohdalla korrelaatioanalysi on hyödyllinen, mutta Big Datan kohdalla se ”loistaa”. Vastaavasti Siegel (2013) esittää päätöspuuanalyysiä käytettäväksi.
Korrelaatio
Korrelaation laskemiseen on olemassa ainakin kaksi vaihtoehtoa. Lineaarista korrelaatiota laskettaessa käytetään Pearsonin tulomomenttikorrelaatiokerrointa (Kaava 1). Kaava on nimetty kehittäjänsä Karl Pearsonin (Kuva 1) mukaan. Järjestysasteikollisten muuttujien tilanteessa voidaan käyttää Spearmanin järjestyskorrelaatiota. (Grönroos, 2003)
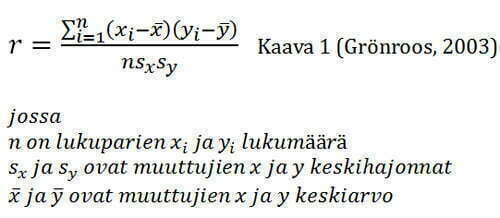
Pearsonin tulomomenttikorrelaatiokerroin kuvaa kahden vähintään intervalliasteikollisen muuttujan välisen keskinäisen lineaarisen riippuvuuden voimakkuutta. Pearsonin tulomomenttikorrelaatiokertoimen kaava on muodostettu niin, että sen arvo vaihtelee välillä -1…1, jossa luku -1 kuvaa täydellistä negatiivista riippuvuutta ja luku 1 täydellistä positiivista riippuvuutta. Pearsonin tulomomenttikorrelaatiokertoimen arvo 0, kuvaa tilannetta, jossa muuttujien välillä ei ole lineaarista riippuvuutta. (Grönroos, 2003)
Kuvassa 2 on graafisesti esitetty kahden muuttujan välinen positiivinen ja negatiivinen lineaarinen riippuvuus. Lisäksi on mahdollista, että muuttujien välinen riippuvuus ei ole lineaarista, vaan esimerkiksi neliöllistä (Kuva 3) tai muuttujien välillä ei ole riippuvuutta olenkaan (Kuva 4).
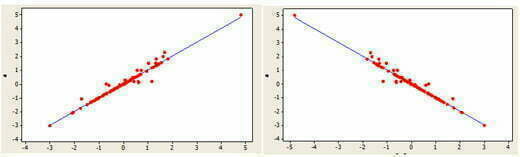
Kuvasta 2 huomataan, että kun muuttujien välillä on positiivinen lineaarinen riippuvuus, pisteet sijoittuvat lähelle suoraa, jolla on positiivinen kulmakerroin. Vastaavasti negatiivisen lineaarisen riippuvuuden tilanteessa pisteet sijoittuvat lähelle suoraa, jonka kulmakerroin on negatiivinen.
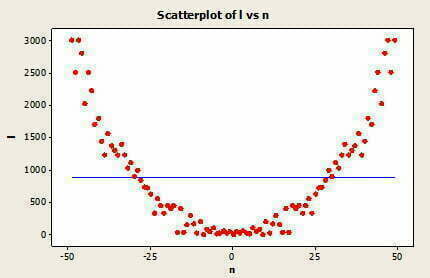
Kuvasta 3 huomataan, että suoran kulmakerroin on tilanteessa 0, mutta pisteistä voidaan silti havaita jonkinlainen, tässä tapauksessa neliöllinen riippuvuus.
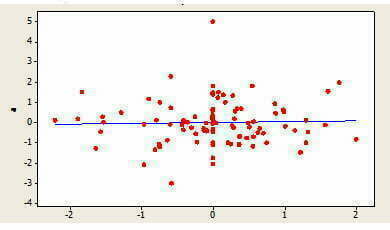
Kuvasta 4 huomataan, että suoran kulmakerroin on tilanteessa 0. Pisteistä ei kuitenkaan havaita minkäänlaista muuta riippuvuutta.
Kaikissa tilanteissa muuttujat eivät ole vähintään intervalliasteikollisia. Tällaisissa tilanteissa pitää korrelaation laskemisessa käyttää järjestyslukuihin perustuvia korrelaatiokertoimia.
Järjestysasteikollisten muuttujien välistä riippuvuutta laskettaessa, korrelaationa käytetään Spearmanin järjestyskorrelaatiota (Kaava 2). Kyseinen korrelaatiokerroin on nimetty kehittäjänsä Charles Spearmanin (Kuva 5) mukaan. (Grönroos, 2013)

Korrelaatioon on kaikkinensa suhtauduttava varauksella, korrelaatio voi myös olla sattuman aiheuttamaa. On lukuisia esimerkkejä, kun asioiden välille on löydetty korrelaatio, joka kuitenkaan ei ole pitänyt paikkaansa. Voidaan esimerkiksi ajatella tilannetta, jossa todetaan Suomessa syötävän paljon jäätelöä kesällä. Samoin hukkumiskuolemat ovat Suomessa kesällä valitettavan yleisiä. Näiden välille pystytäänkin löytämään korrelaatio, jonka mukaan hukkumiskuolemien määrää kesällä Suomessa voidaan selittää suurella jäätelönsyöntimäärällä. Asiaa tarkemmin ajatellen voidaan helposti todeta, että tässä on kyse puhtaasta sattumasta.
Päätöspuut
Eräs tapa Big Datan analysointiin on päätöspuut (decision trees). Siegelin mukaan ne ovat osa ennakoivaa analytiikkaa (Predictive Analytics = PA). Ennakoiva analytiikka on tekniikka, joka oppii kokemuksesta (data) ennakoidakseen yksilöiden käytöstä tehdäkseen parempia päätöksiä. (Siegel, 2013)

Kuvassa 6 on yksinkertainen esimerkki päätöspuusta. Kyseisen puun avulla analysoidaan asuntolainan maksua. Kyseisen päätöspuun perusteella voidaan todeta, että jos talletuskorko on pienempi kuin 7,98% asuntolainan ennakkomaksun todennäköisyys on 3,8%. Vastaavasti, jos talletuskorko on suurempi kuin 7,94, asuntolainan ennakkomaksun todennäköisyys on 19,2%. (Siegel 2013)
Yhteenveto Big Datasta
Nykyinen Big Dataan liittyvä kehitys tarjoaa monia mahdollisuuksia yrityksille ja muille, kuten terveydenhuoltoon. Menetelmistä on oikein käytettynä hyötyä, kunhan muistetaan, että datan määrä itsessään ei ratkaise datan analysointiin liittyviä ongelmia. Tilastotieteen professori David Spiegelhalter Cambridgen yliopistosta toteaa Big Datasta seuraavaa. Hänen mukaansa monet pienen datan ongelmat eivät poistu siirryttäessä Big Dataan – ongelmat vain pahenevat. Tilastotieteilijät ovat käyttäneet viimeiset 200 vuotta tutkien millaisia ongelmia mahdollisesti kohtaamme, kun yritämme ymmärtää maailmaa datan avulla. Vaikka data on isompaa, nopeampaa ja halvempaa, se ei poista datan analysointiin liittyviä ongelmia. (Harford, 2014)
Konsultit suhtautuvat Big dataan naivisti ja on todettu, että esimerkiksi USA:n terveydenhuoltojärjestelmä voisi säästää 300 biljoonaa dollaria vuodessa – 1000 dollaria USA:laista kohden vuodessa soveltamalla Big dataan perustuvia järjestelmiä. Vaikka Big Data lupaa paljon tutkijoille, yrittäjille ja hallituksille, olemme tuomittuja epäonnistumaan, jos unohdamme keskeisiä tilastomatemaattisia asioita. (Harford, 2014)
Lähteet:
- Anderson, C., Kesäkuu 2008. The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. Wired Magazine
- Grönroos, M., 2003. Johdatus tilastotieteeseen kuvailu, mallit päättely. 1. Painos, Oy Finn Lectura Ab
- Harford, T., Maaliskuu 2014. Big data: are we making a big mistake? Financial Times
- Mayer-Schönberger, V. & Cukier, K., 2013. Big Data A Revolution That Will Transform How We Live, Work and Think. 1. Painos, John Murray
- McAfee, A. & Brynjolfson, E., Lokakuu 2012. Big Data: The Management Revolution. Harvard Business Review
- Siegel, E., 2013. Predictive Analytics, The Power to Predict who Will Click, Buy, Lie, or Die. 1. Painos, John Wiley & Sons, Inc.
Internet -lähteet:
- http://www.york.ac.uk/depts/maths/histstat/people/pearson_k.gif
- http://www.york.ac.uk/depts/maths/histstat/people/spearman.gif
Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.